Parallel Nix evaluation


The Nix user experience is significantly affected by the speed of the Nix expression evaluator.
Nixpkgs and NixOS have grown massively in recent years, and continue to grow.
This means that operations like nix search nixpkgs or evaluating NixOS system configurations take increasing amounts of time.
For instance, listing all packages (nix-env -qa) took less than 3 seconds in Nixpkgs 16.03, but more than 15 seconds in 24.05; evaluating a small NixOS configuration (closures.lapp.x86_64-linux) finished in less than half a second in 16.03 but needs more than 3 seconds today.
Similarly, many users have large flakes that take a long time to evaluate, either in CI or on their own systems (for example when running nix flake check).
Many improvements have been made to the Nix evaluator in recent times, but one obvious avenue for improvement has not been taken so far: parallel evaluation. The Nix evaluator has always been single threaded, which means that Nix hasn’t been able to utilize all those wonderful CPU cores available on modern systems—yet.
At Determinate Systems we’ve recently implemented a parallel evaluator, currently available in a draft PR. It already gives a substantial performance improvement—speedups of a factor 3-4 are typical. In this blog post, we describe some of the work that was needed to achieve parallelism, preceded by a short overview of the inner workings of the evaluator.
How Nix evaluation works
In the Nix evaluator, every value is represented as a 24-byte (3-word) structure that consists of a type field and a type-dependent payload. The type is a tag such as “integer”, “Boolean” or “lambda.” For example, the attribute
x = 2;produces the value

In principle, purely functional languages like Nix are ideal for parallel evaluation, because values are immutable.
This means that the pointer to the value of x can be freely shared between threads, as we don’t have to worry about the value getting updated by one thread while another is accessing it.
There is one exception, however, to the immutability of values: thunks. These are the mechanism by which lazy evaluation is implemented. A thunk represents a delayed computation, or closure, that is overwritten in place by the result of the computation, if and when the result is needed. A thunk consists of two pieces of information:
- A pointer to an abstract syntax representation of the definition of the value (in compiled languages, this would be a pointer to the compiled code, but the Nix evaluator is an interpreter, not a compiler).
- A pointer to the environment, which is a data structure that records all the variables that are in scope.
In an expression like
let x = 1; in let y = 2; in <E>, for instance, the environment of the thunk for expression<E>maps the variablesxandyto their respective values.
As an example, consider the expression
let x = 2; y = 3; z = x * y;in zThe value z is initially represented as a thunk:
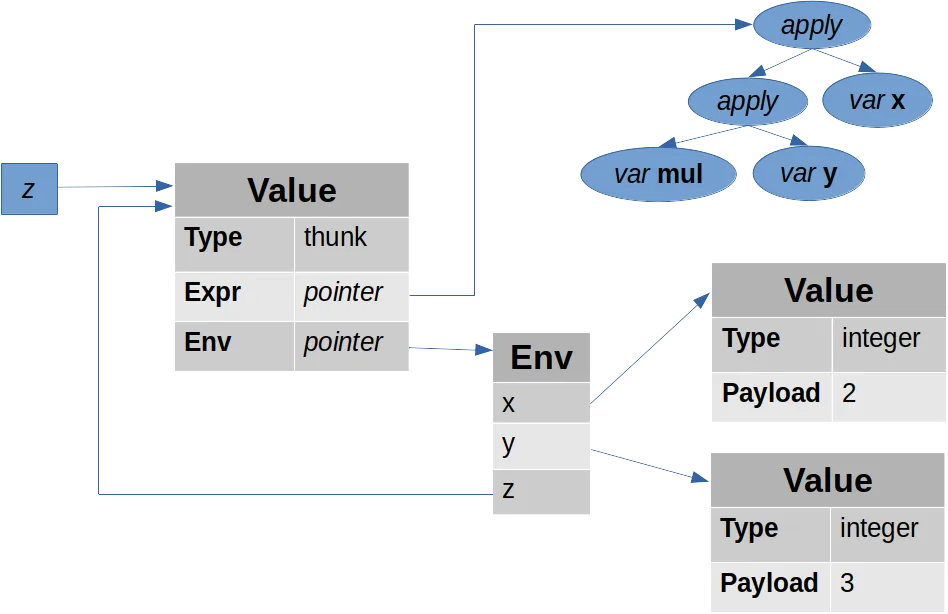
If z is never needed, then z will forever remain a thunk.
But if another expression needs z, the thunk will be forced, meaning that the expression x * y will be computed using the environment that maps x to 2 and y to 3, and thunk is overwritten:

Any subsequent use of z will see the final value 6, so z will be evaluated at most once.
Making the evaluator thread safe
To speed up operations like nix search nixpkgs, we would like to distribute the work of evaluating the attributes in Nixpkgs across multiple threads.
As noted above, only thunks represent a difficulty; “final” values like integers or attribute sets can be accessed in parallel since they’re never updated.
To handle thunks correctly and efficiently, we have these requirements:
-
No thread should ever see a “half-updated” thunk, for example one where the “type” field has been changed to “integer” but the integer payload is in an undefined state.
-
A thunk should not be evaluated more than once. Thus, if a thunk is being evaluated by one thread, other threads that need the result of the thunk should wait (or do other work).
-
Support for multi-threaded evaluation should not have a negative impact on single-threaded performance or memory consumption. This means, for instance, that we can’t just wrap every value in a mutex.
In addition, the changes should be minimally invasive to the current evaluator.
The approach we took is fairly straightforward:
-
The “type” field in values is now an
std::atomic. This allows its state transitions to be done using atomic compare-and-swap instructions, and enables the necessary compiler and CPU memory barriers that ensure that threads see changes to values in the right order. -
The payload of a thunk value is updated to its final value before the type is updated. Thus, if a thread sees a value with an immutable type (for example “integer”), then its payload (for example the integer value) is also valid.
-
There are three new value types:
- Pending denotes a thunk that is being evaluated by a thread, and has no other threads waiting for it.
- Awaited denotes a thunk that is being evaluated by a thread, and has other threads waiting for it.
- Failed denotes a thunk whose evaluation threw an exception.
Its payload stores an
std::exception_ptrthat allows other threads to re-throw the exception if needed.
-
The lifecycle of a thunk is as follows:
-
The value is initialized as a thunk.
-
When a thread forces a value that has type “thunk”, it sets its type to “pending”. This is done using an atomic compare-and-swap to ensure that only one thread will actually evaluate the thunk.
-
When a thread forces a value that has type “pending”, it registers itself in a list of waiters (stored separately from the value) and sets the type of the value to “awaited” (using an atomic compare-and-swap to handle the case where the first thread has just finished the value). It then waits to be woken up by the first thread when it has finished with the value.
-
When a thread finishes evaluating a thunk, it updates the payload of the value, and then does an atomic swap to change the type to its final type. If the previous type was “pending”, that’s all it needs to do, since no other threads are waiting. If it was “awaited”, it wakes up the threads that are waiting.
-
Beyond thunk handling, a couple of other data structures in the evaluator had to be made thread-safe. Usually it was sufficient to wrap them in a mutex, but some data structures are highly contended and so required special handling to make them performant. In particular the symbol table, which ensures that every identifier is stored in memory only once, was rewritten to make symbol access lock-free.
Results
Currently only two nix subcommands distribute work across multiple threads.
This command shows the contents of the nix flake:
nix flake show --no-eval-cache --all-systems --json \ github:NixOS/nix/afdd12be5e19c0001ff3297dea544301108d298On a Ryzen 5900X (12 cores), the single-threaded evaluator takes 23.70s. The multi-threaded evaluator brings this down to 5.77s (using 12 threads), a 4.1x speedup.
This command searches the contents of Nixpkgs:
nix search --no-eval-cache github:NixOS/nixpkgs/bf8462aeba50cc753971480f613fbae0747cffc0 ^This went from 11.82s to 3.88s (using 16 threads), a 3.0x speedup.
This is less than for the previous benchmark because there are more shared dependencies (for example, most threads cannot make progress until the stdenv value has been computed).
Trying it out
The multi-threaded evaluator still has a couple of concurrency bugs that need to be sorted out, but if you do want to try it out, you can get it by running:
nix shell github:DeterminateSystems/nix-src/multithreaded-evalYou then need to set the environment variable NR_CORES to the number of threads that Nix should use.
Here’s an example:
NR_CORES=8 nix search --no-eval-cache nixpkgs helloNext steps
In the near future, we will make more Nix subcommands multi-threaded, such as nix flake check.
In addition, evaluations of single-flake output attributes such as NixOS system configurations should exploit parallelism automatically.
One way to do this would be to distribute derivation attributes across threads.
Written by
Eelco started the Nix project as a PhD student at Utrecht University. He is a co-founder of Determinate Systems, alongside Graham Christensen, and a member of the Nix team.